Byte Latent Transformer (BLT)를 쉽게 이해해 보자
최근 메타에서 공개한 Byte Latent Transformer (BLT)를 정리한 포스트입니다.
바로 일주일 전 Meta에서 토크나이저(Tokenizer) 없이 Byte 단위로 문자를 입력받아 추론을 수행하는 트랜스포머(Transformer) 기반 거대언어모델(Large Language Model; LLM) Byte Latent Transformer (BLT)를 공개했습니다. 이번 포스트에서는 BLT의 개념에 대해 쉽게 풀어써 보려고 합니다.
Paper: Byte Latent Transformer: Patches Scale Better Than Tokens
Table of Contents
배경
대부분의 거대언어모델은 대부분 트랜스포머(Transformer)를 기반으로 합니다. 트랜스포머는 문자열을 토크나이저(Tokenizer)를 사용해 토큰 시퀀스로 변환한 후 입력 받습니다. 최근에는 sub-word 기반의 Byte Pair Encoding (BPE) 토크나이저가 자주 사용되고 있습니다.
기존 LLM은 토크나이저를 활용한 토큰화 과정을 제외하고는 End-to-End 방식으로 학습됩니다. 이로 인해 토큰화 과정에서 편향, Domain/Modality 민감성, 입력 문자열에 대한 민감성과 같은 문제가 발생합니다. 그렇다고 바이트(문자) 단위로 모델을 학습하는 것은 어텐션 계산량 $O(N^2)$ 이 기하급수적으로 늘어나기 때문에 실질적으로 힘들었습니다.
또한 기존 LLM은 토큰 예측 난이도에 관계없이 모든 토큰 생성에 동일한 계산 자원을 할당합니다. 이것은 성능 면에서는 괜찮을지 몰라도 효율성 면에서 크게 떨어집니다.
BLT는 이러한 부분들을 개선하고자 바이트 단위 입력을 받으면서도 트랜스포머를 효율적으로 학습/예측하도록 설계된 모델입니다.
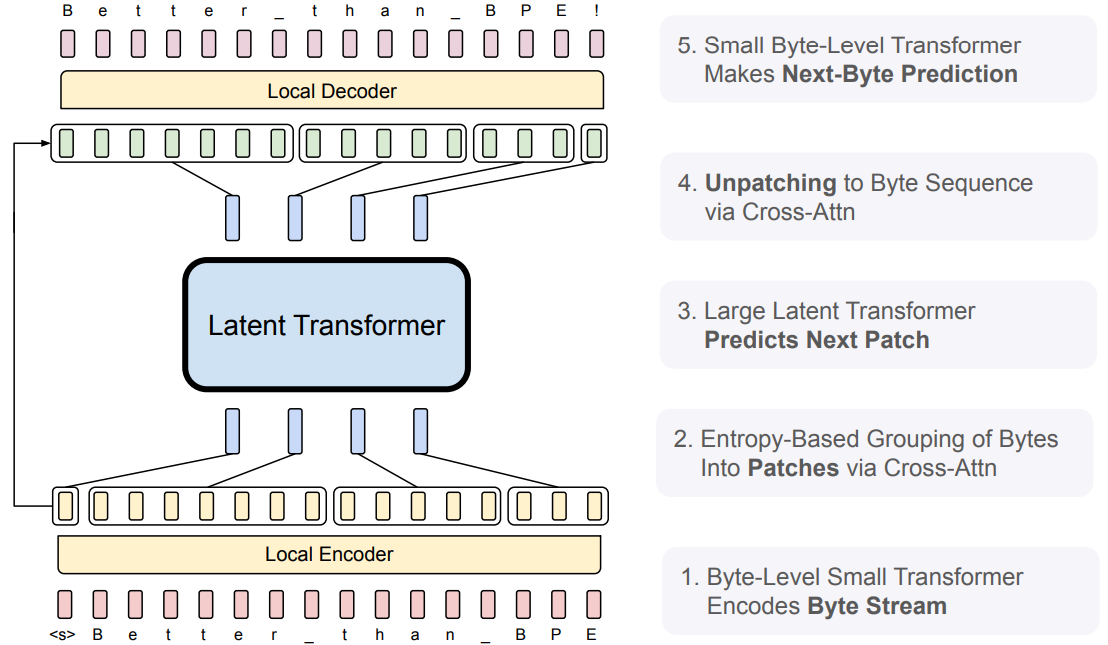
BLT는 크게 두 개의 Local Model (Encoder Transformer, Decoder Transformer)과 하나의 Latent Global Transformer로 구성되어 있습니다. 여기서 Local Encoder는 바이트를 패치로 변환하고, Local Decoder는 패치를 다시 바이트로 변환하는 역할을 합니다. 일종의 end-to-end 학습을 위한 토크나이저 모델로 볼 수 있습니다. 자세한 설명은 BLT 모델 구조 부분에서 설명하겠습니다.
패치(Patch)
패치(Patch)란 입력 바이트(문자)를 하나의 그룹으로 묶은 것 입니다. 넓은 의미에서 토큰도 일종의 패치로 볼 수 있습니다.

위 그림은 다양한 패칭(Patching) 방법의 예시를 보여주고 있습니다. 패칭 방법에는 다음과 같은 유형이 있습니다.
- N-Strided 방식: N개의 바이트를 묶어 하나의 패치로 만드는 방법.
- BPE 방식: sub-word의 등장 빈도수를 기반으로 패치를 생성.
- 엔트로피 기반 BPE 방식: 단어의 엔트로피를 기반으로 패치를 생성.
- Space 방식: 공백을 기준으로 패치를 생성.
BLT와 기존 트랜스포머 기반 모델의 가장 큰 차이점은 패칭 방식에 있습니다. 기존 모델은 학습 과정과는 별개로 고정된 패칭 방식을 사용하기 때문에, 모델의 분포가 바뀌어도 패치는 변하지 않았습니다. 반면, BLT는 end-to-end로 패칭 모델까지 함께 학습합니다. 따라서 동일한 문장이 입력되더라도 학습이 진행됨에 따라 패치가 달라질 수 있습니다.
엔트로피 패칭(Entropy Patching)
BLT는 엔트로피 기반의 패칭 방법을 채택하였습니다. 바이트 단위로 입력받는다고 했는데, 왜 패칭이 필요한지에 대해 의아해 하실 수 있습니다. BLT는 Local Encoder를 통해 바이트 단위 입력을 패치로 그룹화 합니다. 이 부분도 마찬가지로 BLT 모델 구조 부분에서 자세하게 설명하겠습니다.
엔트로피 패칭은 엔트로피 값이 유사하거나 변화 폭이 적은 인접한 바이트들을 하나의 패치로 그룹화하는 방식입니다. 먼저, $i$ 번째 바이트를 $x_i$ , 언어 모델의 분포를 $p_e$ , 바이트 Vocabulary를 $\mathcal{V}$ 라고 한다면 $i$ 번째 바이트에 대한 엔트로피 $H$ 는 다음과 같이 정의할 수 있습니다.
\[H(x_i) = \sum_{v \in \mathcal{V}} p_{e}(x_i = v | x_{<i}) \log{p_e(x_i = v | x_{<i})}\]BLT 논문에서는 엔트로피를 사용해 각 패치간의 경계(Patch Boundary)를 나누는 두 가지 방식을 소개 했습니다.
Global Constraint \(H(x_i) > \theta_g\)
Monotonic Constraint \(H(x_i) - H(x_{i-1}) > \theta_\gamma\)
첫 번째 Global Constraint는 엔트로피 값이 Global Threshold $\theta_g$ 보다 클 때 해당 바이트를 패치의 경계로 간주하는 방식입니다. 두 번째 Monotonic Constraint는 이전 바이트와 현재 바이트 간의 엔트로피 갭이 Threshold $\theta_{\gamma}$ 보다 클 때, 현재 바이트를 패치의 경계로 간주하는 방식입니다.
다음과 같은 문장이 있다고 해 봅시다.
“Daenerys Targeryen is in Game of Thrones, a fantasy epic by George R.R. Martin.”
아래 그림은 Global Constraint를 이용해 위 문장을 엔트로피 패칭으로 처리하는 예시입니다.

“George R.R. Martin.>”에서 첫 번째 글자인 “G”의 다음 바이트에 대한 엔트로피는 $\theta_g$ (Global Trheshold)보다 높습니다. 그리고 이어 나오는 “e” 부터 문장의 끝인 “>” 까지의 엔트로피는 $\theta_g$보다 낮습니다. 따라서 “G”와 “eorge R.R. Martin.>”는 서로 다른 패치에 속하게 됩니다.
BLT 모델 구조
BLT는 Local Encoder, Local Decoder, Latent Global Transformer 세 가지 모델로 구성되어 있습니다.
- Local Encoder와 Decoder는 트랜스포머의 Encoder-Decoder를 의미하는게 아닙니다. 바이트 입력을 패치로 인코딩, 패치를 바이트로 디코딩하기 때문에 때문에 붙여진 이름입니다.
- 엔트로피는 현재 시점까지의 바이트 $x_{\leq i}$ 를 사용하여 계산되므로, Local Encoder와 Decoder는 Look-ahead Mask를 사용하여 학습됩니다. 트랜스포머의 Decoder 학습 방식을 따른다고 볼 수 있습니다.
- Latent Global Transfomer는 우리가 익히 알고 있는 트랜스포머 구조와 동일합니다. 다만 토큰 대신 패치를 입력받아 예측한다는 점에서 차이가 있습니다.
로컬 모델과 글로벌 모델은 둘 다 Llama 3 구조를 사용했다고 합니다.
Latent Global Transformer
Latent Global Transfomer $\mathcal{G}$ 는 Autoregressive 트랜스포머 모델이며, 입력 패치 표현 시퀀스 $p_j$ (sequence of input patch representations)를 출력 패치 표현 시퀀스 $o_j$ (sequence of output patch representations)로 변환하는 역할을 수행합니다. 논문에서는 Latent Global Transfomer에 현재 패치까지만 어텐션을 계산하도록 하는 Block-causal Attention을 적용했다고 합니다. Latent Global Transformer는 Local Model에 비해 사이즈가 훨씬 크기 때문에 BLT 학습/추론 과정에서 대부분의 연산을 차지합니다.
Local Encoder
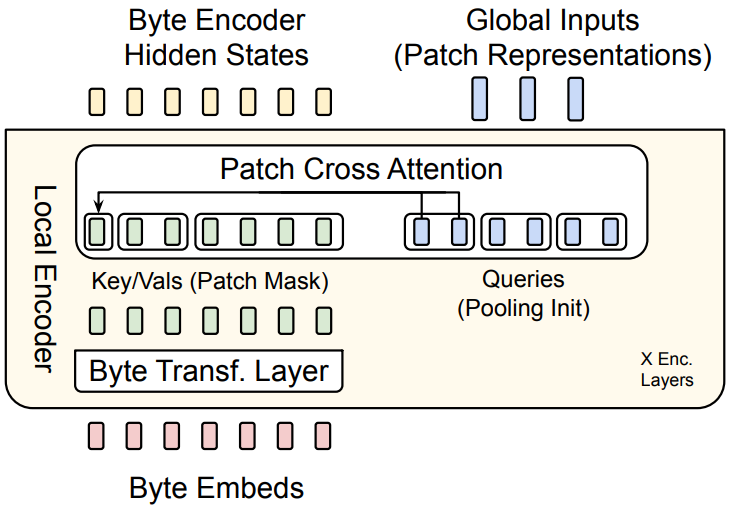
Local Encoder $\mathcal{E}$ 는 입력 바이트 임베딩 $b_i$ 를 패치 표현 $p_j$ 로 효율적으로 변환해야 하기 때문에 Latent Global Transformer $\mathcal{G}$ 에 비해 훨신 적은 수의 트랜스포머 레이어로 구성됩니다. 기존 트랜스포머와 다른 점은 각각의 트랜스포머 레이어 뒤에 패치 크로스 어텐션이 붙습니다.
Hash n-gram Embeddings
먼저 입력 바이트 임베딩 $b_i$는 행렬 $M \in R^{256 \times h_{\epsilon}}$ 을 통해 $x_i$ 로 임베딩됩니다. 여기서 256은 바이트 임베딩의 차원, $h_{\epsilon}$ 은 Local Encoder $\mathcal{E}$ 의 표현형 차원입니다.
논문의 저자들은 표현형의 강건성을 높히고, 이전 바이트의 정보들을 현재 바이트에 제공하기 위해 해쉬 임베딩을 $x_i$ 에 더해주었습니다. 해쉬 임베딩을 더하는 과정은 아래와 같습니다. 우선 현재 임베딩 $x_i$를 기준으로 바이트 n-gram $g_{i,n}$ 은 다음과 같이 정의됩니다.
\[g_{i,n} = \{b_{i-n+1} \cdots b_i \}\]논문에서는 3-gram 바이트부터 8-gram 바이트를 계산한 후, 해쉬 함수와 해쉬 임베딩 테이블 $E^{hash}_{n}$ (임베딩 레이어)을 통해 각각의 해쉬 n-gram 임베딩을 계산하고 현재 바이트 임베딩에 더해줍니다. 수식으로 나타내면 다음과 같습니다.
\[e_i = x_i + \sum_{n=3,\dots,8}{E^{hash}_n (Hash(g_{i,n}))}\] \[Hash(g_{i,n}) = RollPolyHash(g_{i,n})\%|E^{hash}_{n}|\] \[RollPolyHash(g_{i,n}) = \sum_{j=1}^{n} b_{i-j+1}a^{j-1}\]마지막 RollPolyHash의 $a$는 임의로 선택된 10개의 소수입니다. $Hash(g_{i,n})$ 에서는 최대 해쉬 값이 임베딩 테이블 $E^{hash}_n$ 의 최대 인덱스를 넘지 않도록 Normalize 하고 있는 것을 볼 수 있습니다. 위 과정을 통해 계산된 임베딩 $e_i$ 는 Byte Transformer Layer (그림) 을 통과하게 됩니다.
Multi-Headed Cross-Attention
Byte Transformer Layer를 통과한 임베딩은 패치와의 크로스 어텐션에 사용됩니다. 이를 위해 먼저 각 바이트의 엔트로피를 계산하여 패치 경계를 설정한 뒤, 각 패치 그룹에 대해 임베딩을 계산합니다.
Local Encoder $\mathcal{E}$ 의 첫 번째 레이어에서는 임베딩이 Byte Transformer Layer를 통과한 시점에 아직 패치 임베딩이 생성되지 않았습니다. 따라서 첫 번째 레이어에서는 바이트 임베딩을 풀링(Pooling)하여 패치 임베딩을 초기화합니다. 이때 풀링 방식으로는 Mean/Max/Min 풀링을 사용할 수 있습니다. 이후 Local Encoder $\mathcal{E}$ 의 두 번째 레이어부터는 이전 레이어에서 계산된 패치 임베딩을 사용됩니다.
풀링된 패치 임베딩은 Linear Projection Maxtrix $\mathcal{E}C \in \mathbb{R}^{h\epsilon \times (h_\epsilon \times U_\epsilon)}$ 을 통해 사영됩니다. 여기서 $U_\epsilon$ 은 어텐션 헤드의 수입니다. 사영된 패치 임베딩을 Query로, 바이트 임베딩을 Key/Value로 하여 크로스 어텐션이 수행됩니다. 크로스 어텐션 과정은 기존 트랜스포머의 크로스 어텐션과 동일합니다.
수식으로 나타내면 다음과 같습니다.
\[P_{0,j} = \mathcal{E}_C\left(f_{\text{bytes}}(p_j)\right), \quad f \text{ is a pooling function.}\] \[P_l = P_{l-1} + W_o \left( \text{softmax} \left( \frac{QK^\top}{\sqrt{d_k}} \right) V \right)\] \[Q_j = W_q(P_{l-1,j}), \quad K_i = W_k(h_{l-1,i}), \quad V_i = W_v(h_{l-1,i})\] \[h_l = \text{Encoder-Transformer-Layer}(h_{l-1})\]위 과정을 이해하기 쉽게 임베딩의 Shape을 통해 살펴보겠습니다.
- 트랜스포머 레이어를 통과한 임베딩 $h_l$ :
(batch_size, sequence_len, encoder_dim) - 엔트로피 계산으로 패치 경계 설정 후 경계 내 바이트 임베딩 풀링 $f_{\text{bytes}}(p_j)$ :
(batch_size, 1, encoder_dim) - 사영된 풀링 임베딩 $P_{0,j}$ :
(batch_size, 1, num_header, encoder_dim) - “패치 경계 내 바이트 - 패치” 간 어텐션 $P_l$ :
(batch_size, 1, num_header x encoder_dim)
어텐션을 통해 계산된 패치 임베딩은 이후 Local Encoder $\mathcal{E}$ 의 다음 레이어에서 쿼리 패치 임베딩으로 사용됩니다. 이 때 부터는 초기화를 위한 풀링을 수행하지 않습니다. 이렇게 여러 레이어를 거쳐 생성된 패치 임베딩 $P_l$ 은 Latent Global Transformer의 입력으로 사용됩니다.
Local Decoder
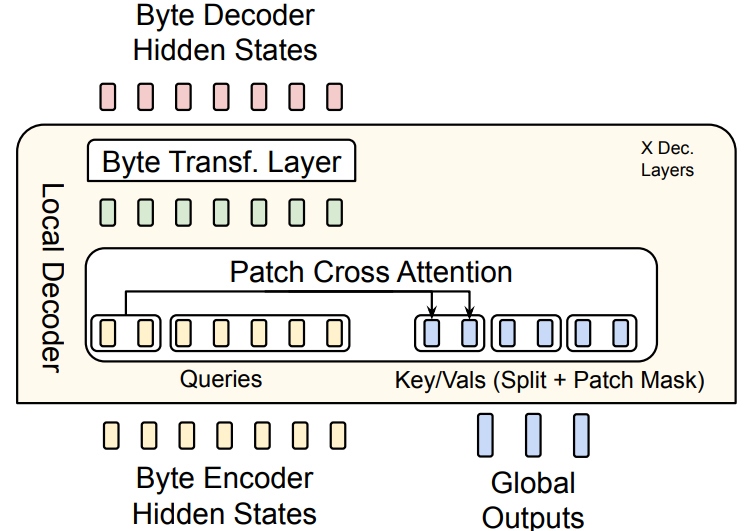
Local Decoder $\mathcal{D}$ 는 Local Encoder $\mathcal{E}$ 와 마찬가지로 Latent Global Transformer $\mathcal{G}$ 에 비해 훨씬 적은 수의 트랜스포머 레이어로 구성됩니다. Local Decoder $\mathcal{D}$ 의 주요 역할은 Latent Global Transforer $\mathcal{G}$ 의 global 패치 표현형 $o_j$ 를 바이트로 변환하는 것입니다.
Local Decoder $\mathcal{D}$ 는 바이트 시퀀스 임베딩과 패치 임베딩을 바탕으로 디코딩을 진행하기 때문에 초기 바이트 시퀀스에 대한 임베딩이 필요합니다. 논문에서는 Local Encoder $\mathcal{E}$ 의 마지막 레이어를 통과한 바이트 시퀀스 임베딩을 초기값으로 사용했습니다. 이후 과정은 Local Encoder $\mathcal{E}$ 와 정반대로 진행됩니다.
먼저 크로스 어텐션을 통해 바이트 패치간 크로스 어텐션이 수행되고, 생성된 바이트 어텐션 값이 Byte Transformer Layer를 통과합니다. 여기서 중요한 차이점은 Local Encoder $\mathcal{E}$ 에서는 바이트가 Key/Value, 패치가 Query였다면 Local Decoder $\mathcal{D}$ 에서는 바이트가 Query, 패치가 Key/Value가 된다는 것 입니다..
이 과정을 수식으로 나타내면 다음과 같습니다.
\[D_0 = h_{l\mathcal{E}}\] \[B_l = D_{l-1} + W_o \left( \text{softmax} \left( \frac{Q K^\top}{\sqrt{d_k}} \right) V \right),\] \[\text{where} \quad Q_i = W_q(d_{l-1,i}), \quad K_i = W_k(D_C(o_j)), \quad V_i = W_v(D_C(o_j))\] \[D_l = \text{Decoder-Transformer-layer}_l(B_l)\]여기서 $h_{l\mathcal{E}}$ 는 Local Encoder의 마지막 레이어를 통과한 바이트 임베딩이며, $D_C$ 는 Latent Global Tranformer $\mathcal{G}$ 의 output과 바이트 임베딩 간의 차원을 맞춰주기 위한 Split 연산입니다.
실험결과
저자들은 BLT를 Llama 2 데이터 셋과 BLT-1T 데이터 셋을 사용하여 학습하였습니다. BLT-1 데이터 셋은 Datacomp-LM에서 공개된 pre-training용 데이터 셋과 다양한 출처에서 수집한 데이터 셋으로 구성되어 있다고 합니다.
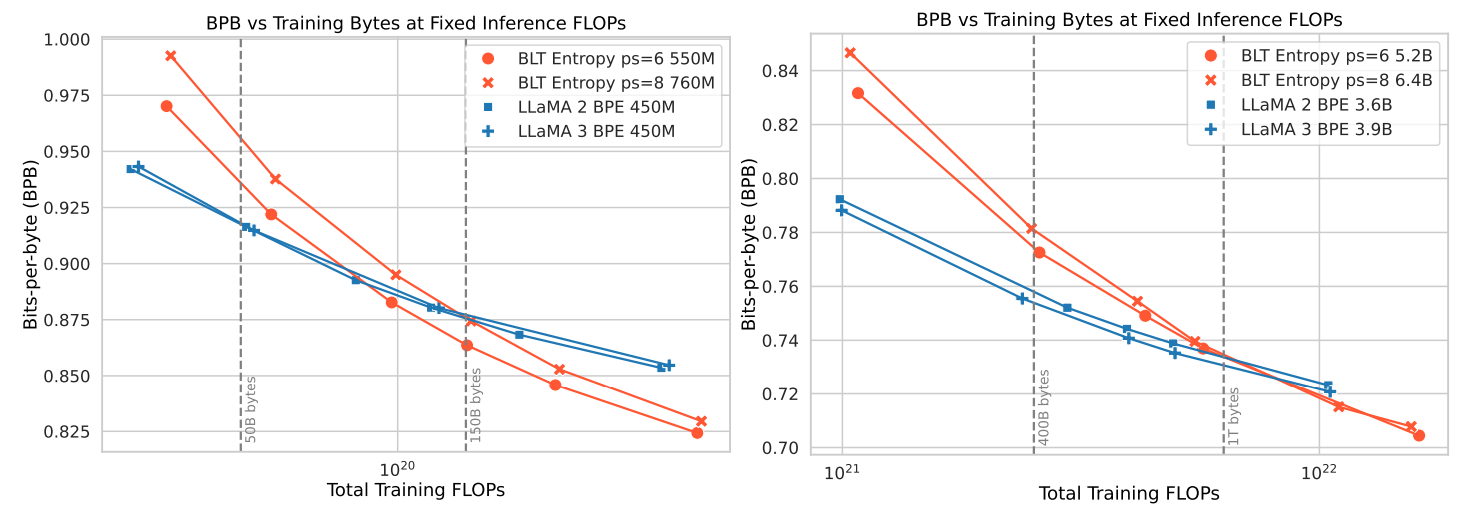
Training FLOPs에 따른 Bits-per-byte (BPB) 추이 그래프입니다. BLT는 토크나이저를 사용하는 모델과 달리 학습 과정에서 동일한 단어에 대해 서로 다른 패치를 생성할 수 있습니다. 이로 인해 고정된 토큰에 기반한 Perplexity는 의미를 갖기 어렵습니다. 따라서 저자는 바이트 예측에 필요한 평균 비트 수(BPB)를 지표로 사용하였습니다.
학습 초기에는 LLaMA 모델에 비해 BPB가 높지만 학습이 진행됨에 따라 BPB가 LLaMA 보다 낮아지는 것을 볼 수 있습니다.
BLT 학습 초기에는 Local Encoder가 예측하는 바이트들의 엔트로피가 높을 것으로 예상됩니다. 따라서 극단적인 경우, 패치가 바이트 단위로 생성될 수도 있습니다. 이로 인해 초기 학습이 불안정하여 BPB 값이 높게 나타나는 것 같습니다. 그러나 학습이 진행되면서 적절한 패치가 생성되기 시작하고, 이것이 모델의 수렴 속도를 높인 것으로 보입니다.
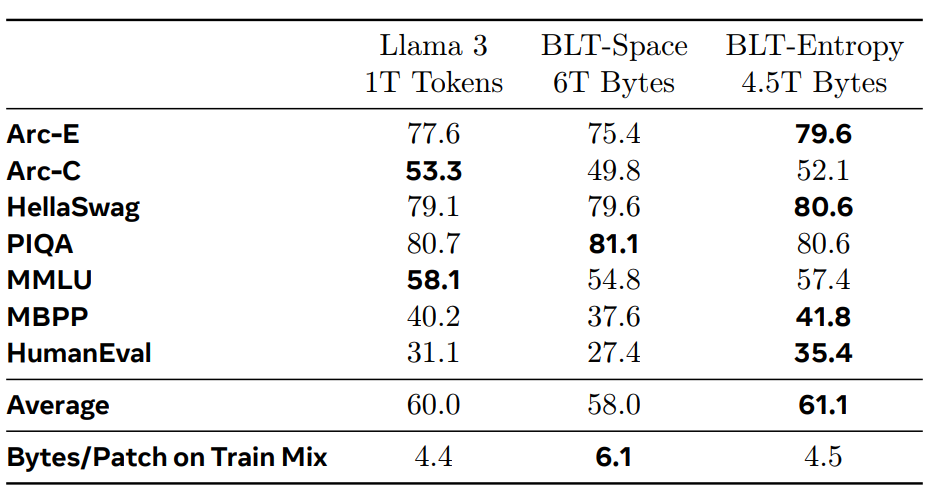
동일한 자원으로 학습된 모델 간 벤치마크 결과입니다. BLT는 8B 모델입니다. Entropy 패치를 사용한 BLT가 Llama 3 토크나이저를 활용해 학습된 모델보다 우수한 성능을 보였다는 점이 인상적입니다.
정리
BPE 같은 토크나이저의 Vocabulary 크기가 무한히 커질 경우, BLT의 엔트로피 기반 패칭과 유사한 방식으로 동작하지 않을까 생각했습니다. 다만, 실제로 그렇게 구현하지 못한 이유는 Embedding Layer와 Pooler의 계산량이 크게 증가하고, 각 Vocabulary의 표현형을 학습하기 위해 더 많은 데이터가 필요했기 때문이겠죠. BLT는 이러한 문제점을 해결해 보려고 했던 것 같아서 굉장히 흥미롭게 읽은 논문이었습니다.
구현이 어렵지는 않아서, 조만간 시간이 나면 구현해 GitHub 업로드해보겠습니다.