LLM 강화학습 알고리즘(RLHF, DPO) 간단 정리
LLM 학습에 사용되는 강화학습 알고리즘들을 간략하게 정리한 포스트입니다.
LLM 강화학습 알고리즘(RLHF, DPO) 간단 정리
Policy Gradient Method
- Gradient estimator
- $\pi_{\theta}$ 는 stochastic policy
- $\hat{A_{t}}$는 estimator of the advantage function at timestep $t$
- 현재 상태에서 행동 $a_t$를 하는 것이 얼마나 좋은지를 나타낸다
- $a_{t}$와 $s_{t}$는 각각 timestep $t$에서의 행동(action)과 상태(state)
- Loss
- 기본 Policy 최적화는 policy gradient의 변화가 급격하여 학습이 잘 안되는 문제점이 존재함
Trust Region Policy Optimization (TRPO)
- Policy gradient method의 문제 점을 해결하기 위해 policy의 변화율에 제약을 추가한 TRPO가 등장
Objective function (the “surrogate” objective)
\[\begin{align} &\max\limits_{\theta} \enspace \hat{\mathbb{E}_{t}}[\frac{\pi_{\theta}(a_{t}|s_{t})}{\pi_{\theta_{old}}(a_{t}|s_{t})}\hat{A_{t}}] \\ & \text{subject to} \enspace \hat{\mathbb{E}_{t}}[KL[\pi_{\theta_{old}}(\cdot|s_{t}),\pi_{\theta}(\cdot|s_{t})]] \leq \delta. \end{align}\]- 성능은 좋지만 제약조건을 구현하기 까다롭다는 문제가 있음.
Proximal Policy Optimization (PPO)
- TRPO와 비슷한 성능을 내면서도 구현이 간단한 PPO가 제안됨
- Objective
- $r_{t}(\theta)$를 확률비(probability ratio)라 정의하자.
논문에서 제안하는 loss function $L^{CLIP}$은 다음과 같다.
\[L^{CLIP}(\theta) = \hat{\mathbb{E}_{t}}[\min(r_{t}(\theta)\hat{A_{t}}, \text{clip}(r_{t}(\theta), 1-\epsilon, 1+\epsilon)\hat{A_{t}})]\]- clip 함수를 사용함으로써 TRPO의 제약조건과 유사한 효과를 낼 수 있다. 하지만 구현이 훨씬 간단하다.
- Advantage function $A$의 부호에 따라 $L^{CLIP}$ 은 다음과 같이 값을 가진다.
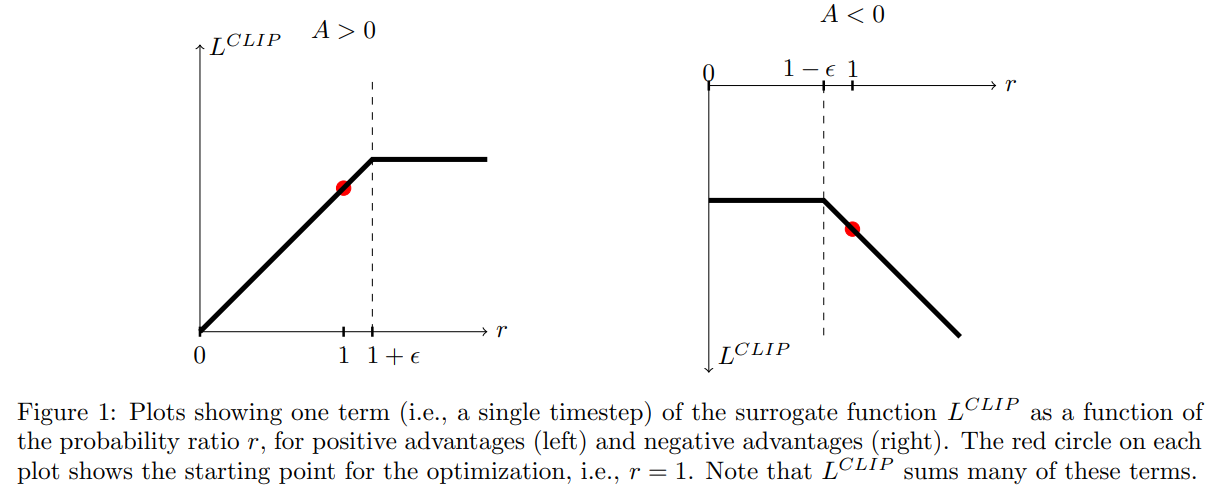
- 위 그림이 나타내는 것은 Advantage function $A$가 양수일 경우 확률비 $r_{t}$가 1보다 너무 높아지지 않게 하겠다는 뜻, $r_{t}$가 1보다 작을 땐 더 학습이 필요하므로 제약을 주지 않음
- 마찬가지로 $A$가 음수일 경우 $r_{t}$가 1보다 너무 작아지지 않도록 제약을 준다. 이 경우 $r_{t}$가 1보다 큰 경우 제약을 주지 않는다. Advantage가 음수이므로 negative action에 대해서는 제약이 없다.
Reinforce ment learning with Human Feedback (RLHF)
- RLHF는 아래와 같이 세 가지 단계로 구성되어 있음
- supervised fine-tuning (SFT)
- preference sampling and reward learning
- RL optimization
- supervised fine-tuning (SFT) Phase
- 일반적으로 dialogue, summarization과 같은 다운스트림 테스크를 학습한 모델 $\pi^{SFT}$ 를 얻기 위해 수행됨
- Reward Modelling Phase
SFT 모델에 prompt $x$를 입력으로 주어 답변 쌍 $(y_{1}, y_{2}) \sim \pi^{SFT}(y|x)$ 들을 생성함.
- 레이블링 작업자는 입력-답변 쌍들에 대해 선호도 $y_{w} \succ y_{l}\enspace|\enspace x$ 를 레이블링 함
- 순서 매기기; $y_w$는 $y$ win, $y_l$은 $y$ lose
- 선호도 모델링에는 Bradley-Terry (BT) 모델이 사용됨
- BT 모델은 인간 선호도(human preference) 분포 $p^{*}$ 를 다음과 같이 정의함
- 여기서 $r^{*}$ 는 ground truth 리워드 모델을 나타냄
- $p^{*}$ 로 부터 샘플링된 데이터셋을 $D= \lbrace x^{(i)}, y_{w}^{(i)}, y_{l}^{(i)} \rbrace_{i=1}^{N}$, $\phi$ 로 파라미터라이징된 모델을 $r_{\phi}(x, y)$ 라 정의하면 선호도 최적화는 다음과 같은 NLL loss로 표현 가능하다
- BT 모델은 인간 선호도(human preference) 분포 $p^{*}$ 를 다음과 같이 정의함
- $\sigma$는 logistic function
- $r_{\phi}(x, y)$는 보통 SFT 모델 $\pi^{SFT}(y|x)$로 초기화 하고, linear layer를 마지막 레이어 뒤에 추가함 (선호도 분류 목적)
- 리워드 함수(모델) $r_{\phi}$의 variance를 낮추기 위해, 선행 연구들은 $E_{x,y \sim D}[r_{\phi}(x,y)] = 0 \enspace \text{for all} \enspace x$로 설정함 (zero mean vector)
- RL Fine-Tuning Phase
- 학습된 reward 함수(모델)을 LM 피드백을 위해 사용함. 최적화 식은 아래와 같음
- 여기서 $\pi_{ref}$는 레퍼런스 policy로 initial SFT 모델 $\pi^{SFT}$를 나타낸다
- 일반적으로 $\pi_{\theta}(y|x)$ 또한 $\pi^{SFT}$로 초기화 됨
- $\beta$는 현재 학습 중인 policy와 레퍼런스 policy간의 차이를 조절하는 파라미터
- 이 최적화 식은 human reference는 최대화 되면서도 기존 SFT 모델 $\pi_{ref}$로 부터 너무 멀어지지 않도록 한다.
- 또한 최적화 식의 두번째 텀(KL Div)은 mode-collapse를 방지함 (높은 reward를 내는 유사한 답변만 생성하는 것을 방지)
- 위 최적화 식은 미분 불가능하다(reward model 때문에). 따라서 RL을 사용하여 학습한다. 예를들어 Policy gradient 방법론을 사용하여 최적화 할 수 있음
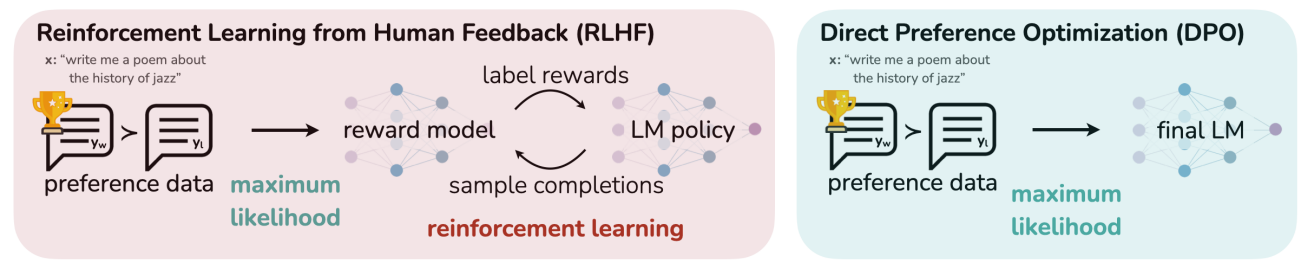
Direct Preference Optimization (DPO)
- RLHF의 학습 불안정성을 해결하기 위해 제안됨
- RLHF의 학습 불안정성은 여러가지 원인이 있겠지만, reward 모델 학습(1차), reward 모델을 사용한 unsupervised LM의 fine-tuning (2차) 과 같이 두 가지 스텝으로 구성된 학습 방식이 주요 원인으로 여겨짐
DPO는 (prompt, chosen answer, rejected answer)를 사용하여 human preference를 학습하려고 시도하였음
- RLHF의 objective function은 아래와 같다.
다양한 선행 연구에서 해당 objective는 general reward function $r$에 대하여 다음과 같은 형태로 바꿀 수 있다는 것을 알아내었다.
\[\pi_{r}(Y|X) = \frac{1}{Z(x)} \pi_{ref}(y|x)\exp(\frac{1}{\beta}r(x,y))\]- 여기서 $Z(x)=\sum_{y} \pi_{ref}(y|x)exp(\frac{1}{\beta}r(x,y))$ 이며 partition function이다.
- 유도식은 맨 아래 Appendix A.1 참고
- 여기서 $Z(x)$를 계산하는 것은 시간이 오래 걸린다 (여러 답변을 생성하고, reward에 forward 한 후 exponential 연산까지 수행해야 하므로)
위 수식에 log를 취하고 reward $r$에 대한 수식으로 바꾸면 다음과 같다.
- 위에서 구한 $r(x,y)$의 ground truth를 $r^{*}(x,y)$로 정의하고 Bradley-Terry 모델 $p^{*}(y_1 \succ y_2 \enspace | \enspace x)$ (RLHF reward modeling pahse 참고)에 넣으면 다음과 같은 수식을 얻을 수 있다.
- Exponential 안에 있는 수식을 최소화하면 Bradley-Terry 모델(human preference)를 최대화 할 수 있다.
- 즉, $\beta\log\frac{\pi^{*}(y_1|x)}{\pi^{ref}(y_1|x)} - \beta\log\frac{\pi^{*}(y_2|x)}{\pi^{ref}(y_2|x)}$ 를 최대화 하면 된다.
- 이것을 Maximum likelihood objective for parameterized policy $\pi_{\theta}$ 형태로 바꾸면 다음과 같다.
- 위 수식이 DPO의 objective이다.
- DPO의 의의는 미분 불가능한 RLHF의 objective를 수식 정리를 통해 미분 가능하게 만들었다는 것이다.
- implicit하게 reward 학습함
Appendix A.1
참고
- 수식 12의 마지막 등식 두 번째 항은 상수 취급할 수 있다. –> 최적화 할 $\pi$가 포함되어 있지 않기 때문에
- 따라서 첫번째 항만 최적화하면 된다. 이때 첫번째 항은 KL Divergence 수식으로 바꿀 수 있다.


This post is licensed under CC BY 4.0 by the author.