DeepSpeed ZeRO를 사용해 거대 모델을 학습해보자
DeepSpeed ZeRO에 대한 설명과 모델 학습 코드를 정리한 포스트입니다.

1. 서론
[Paper] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
DeepSpeed는 Microsoft에서 공개한 대규모 딥러닝 모델 학습을 위한 라이브러리다. DeepSpeed를 이해하려면 먼저 딥러닝 모델의 학습 및 추론에 사용되는 병렬화 방법인 Data Parallelism과 Model Parallelism에 대해 알아야 한다.
간단하게 설명하자면 Data Parallelism은 하나의 GPU마다 모델 전체를 올린 후 데이터를 분산 처리하는 방식이고 Model parallelism은 모델을 나누어 여러 GPU에 올리는 방식이다.
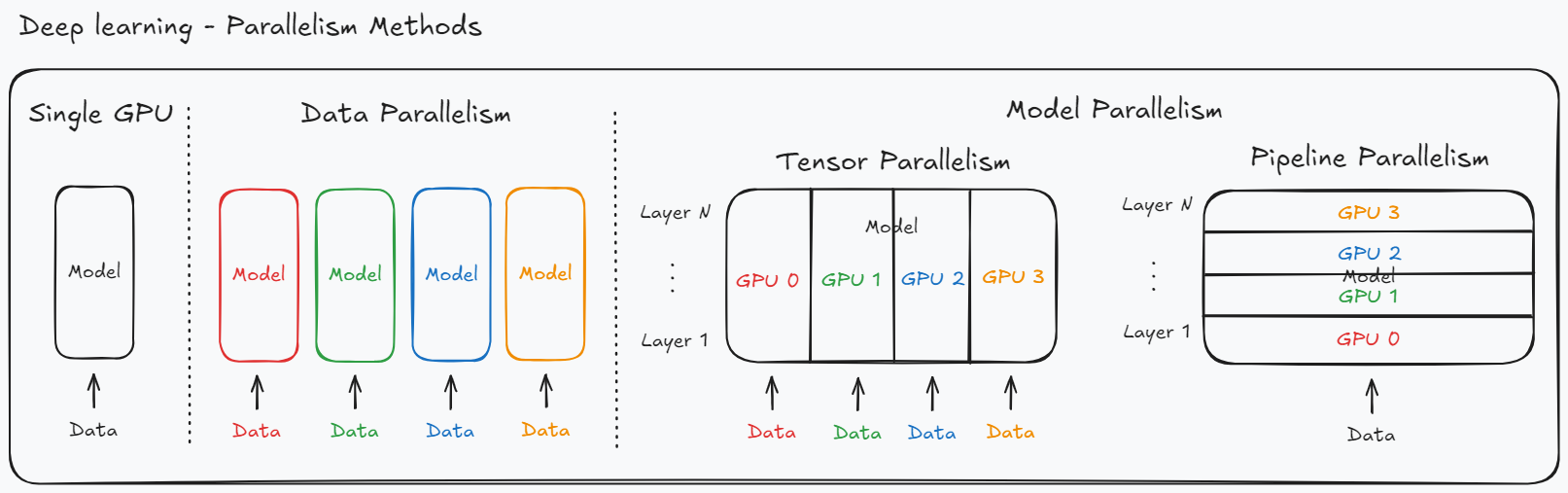
Data Parallel은 Pytorch 프레임워크에서 기본적으로 지원해 쉽게 구현이 가능하고 GPU간 통신 비용이 적다는 장점이 있지만 각각의 GPU의 모델을 전부 로드하기 때문에 Memory Redundancy 문제와 단일 GPU에 로드하기 힘든 큰 모델을 학습할 수 없다는 문제가 존재한다.
Model Parallel은 모델의 크기가 커서 하나의 GPU에서 학습이 불가능 한 경우 사용할 수 있는 방법이다. 여러 GPU에 모델의 파라미터를 나누어 로드하기 때문에 하나의 GPU로는 학습이 불가능한 모델도 학습할 수 있다는 장점이 있지만 Forward, Backward시 GPU 간 통신이 필요하기 때문에 Data Parallel 방식보다 GPU간 통신 비용이 많이 든다는 단점이 존재한다.
두 방식의 장단점을 정리하면 아래와 같다.
- Data Parallelism
- Good compute/communication efficiency
- Poor memory efficiency
- Model Parallelism
- Poor compute/communication efficiency
- Good memory efficiency
DeepSpeed는 ZeRO (Zero Redundancy Optimizer) 분산 처리 효율화 방법을 통해 Data Parallel 방식의 비효율성을 개선하여 대규모 파라미터 모델 학습을 가능하게 하였다.
2. ZeRO (Zero Redundancy Optimizer)
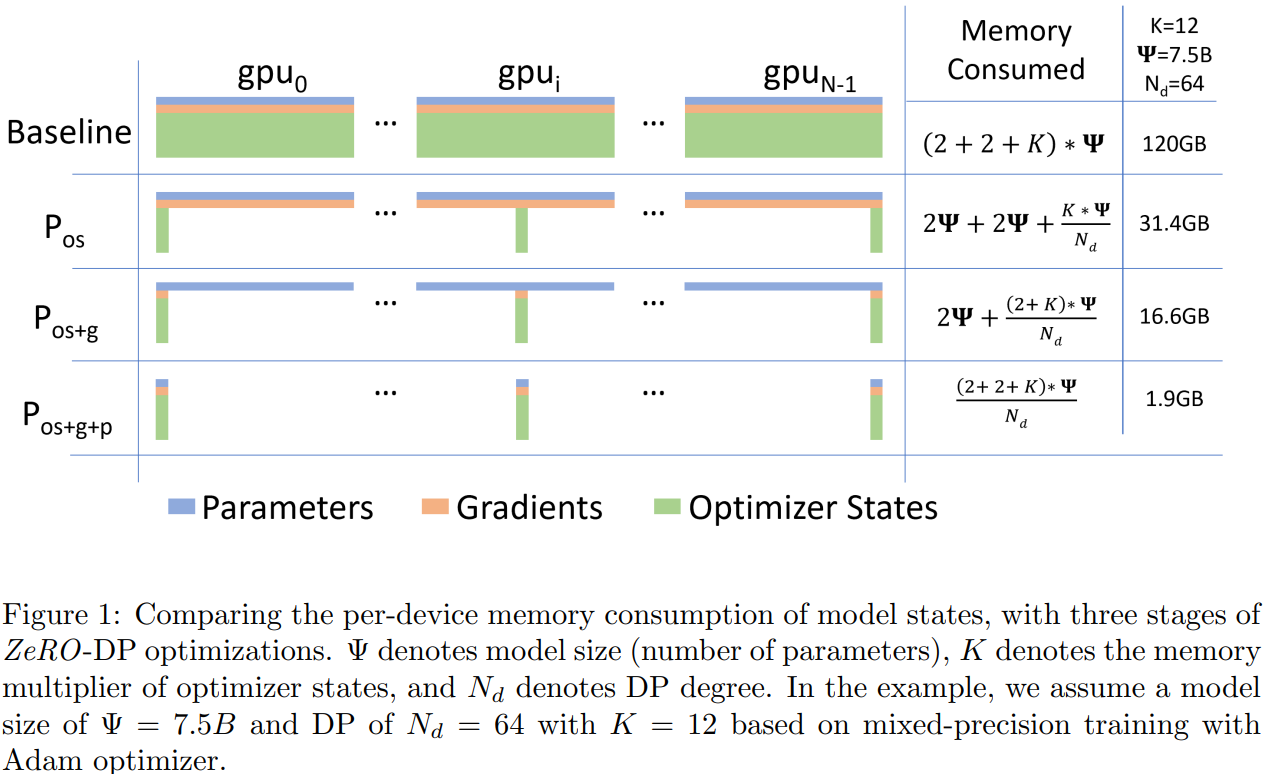
DeepSpeed는 ZeRO를 통해 효율화된 분산 처리를 구현하였다. Microsoft 연구진들은 Model Parallel 과정에서 Optimizer, Gradient, Parameter, Activation Memory의 Redudancy를 발견하였고, 이를 Partitioning하여 해결하고자 하였다.
ZeRO는 각각 ZeRO-1, ZeRO-2, ZeRO-3 세 가지 단계로 구분된다.
- ZeRO-1은 Optimizer States를 Partitioning하며 위 그림의 $P_{os}$ 부분에 해당한다.
- ZeRO-2는 Opimizer States + Gradients를 Partitioning 하며 위 그림의 $P_{os+g}$에 부분에 해당한다.
- ZeRO-3는 Optimizer States + Gradients + Parameters를 Partitioning 하며 위 그림의 $P_{os+g+p}$ 부분에 해당한다.
각 단계는 아래에서 설명하고자 한다.
2-1. ZeRO-1
ZeRO-1은 Optimizer State를 Partitioning한다. 우선 그림을 보면 Model Parameter 보다 Optimizer State가 더 큰 것을 보고 의아해 할 수 있다. Pytorch의 Adam Optimizer를 사용하는 경우를 예로 들어 Optimizer가 어떤 정보를 저장하고 있는지 확인해 보자.
NOTE:
state:
step: 업데이트 횟수exp_avg: gradient의 지수 이동 평균 (1차 모멘텀)exp_avg_sq: gradient 제곱에 대한 지수 이동 평균 (2차 모멘텀)param_groups:
params: 모델 파라미터lr,betas,weight_decay등 각종 하이퍼파라미터 값
‘state’에 저장되어 있는 값만 하더라도 Model Parameter 크기의 2배가 넘어간다. 따라서 ZeRO-1에서는 가장 큰 Memory Redundacy를 차지하는 Optimizer State 전체를 각각의 GPU에 전부 저장하지 않고 N 개의 GPU에 나눠 저장한다. Optimizer State는 Backward 과정에서 필요한데, 이때 GPU 간 All-Gather 연산을 통해 불러와 사용하게 된다.
2-2. ZeRO-2
ZeRO-2는 ZeRO-1에서 더 나아가 gradient까지 partitioning 한다. Backward 수행 후 모델의 모든 weight에 대한 gradient가 계산된다. 계산된 weight를 각각의 GPU에서 모두 저장하고 있는 것은 메모리 비효율적이다. 따라서 ZeRO-2에서는 N 개의 GPU가 계산된 gradient를 나누어 저장한다. 또한, gradient 계산 시 forward 과정에서 계산된 activation 값이 필요하며, Pytorch에서는 backward 과정에 사용하기 위해 이를 각각의 GPU 메모리에 전부 저장해둔다. 이는 상당한 메모리를 차지하므로 ZeRO-2에서는 activation memory 또한 N 개의 GPU가 나눠 저장한다.
Zero-2부터는 N개의 GPU에 Partitioning하지 않고 CPU 메모리에 저장할 수 있는 CPU-Offloading을 지원한다. 이를 통해 GPU 메모리 사용량을 더욱 줄일 수 있게 되었다. 추가로 CPU 메모리 뿐만 아니라 SSD Offloading도 지원한다.
2-3 ZeRO-3
ZeRO-3는 ZeRO-2에 더해 parameter까지 partitioning 한다. ZeRO-1, ZeRO-2와 마찬가지로 N 개의 GPU에 Parameter를 나눠서 저장하며, forward/backward 과정에서는 특정 레이어의 계산이 필요한 순간에 파라미터를 All-Gather 연산을 통해 불러오게 된다. 대개 이 단계까지 오면 모델 학습 시 필요한 GPU 메모리가 부족한 상황이라 CPU-Offloading과 함께 사용하게 된다.
2-4 정리
ZeRO-1에서 ZeRO-3로 갈수록 Memory Redundancy는 줄어들지만 GPU-GPU 혹은 GPU-CPU 간 Communication 비용은 늘어나게 된다. 정리하자면 아래와 같다.
NOTE: Baseline은 ZeRO 적용하지 않은 Model Parallelism
- Momore Redundancy: Baseline > ZeRO-1 > ZeRO-2 > ZeRO-3
- Communication Cost: ZeRO-3 > ZeRO-2 > ZeRO-1 > Baseline
따라서 무작정 ZeRO-3를 사용하는 것은 옳지 않다. 만약 GPU 메모리가 충분해 ZeRO-2, ZeRO-3 둘 다 사용 가능한 상황이면 Communication Cost가 적은 ZeRO-2를 선택하는 것이 더 빠른 학습을 위한 옳은 결정일 것이다. 또한 ZeRO-3는 Parameter를 partitioning 하기 때문에 학습뿐만 아니라 대규모 모델의 Inference에도 도움이 된다.
3. Huggingface Trainer 적용 예
DeepSpeed는 Configuration만 설정하면 손쉽게 사용 가능하며, Configuration 파일은 JSON 파일 형태로 구성하면 된다. 자세한 설명은 DeepSpeed Docs 페이지에서 확인할 수 있다.
3-1. Configuration 설명
fp16: {enable: true|False|'auto'}
- fp16 학습/추론 여부 설정
bf16: {enable: true|False|'auto'}
- bf16 학습/추론 여부 설정
- 주의할 점은 Gradient Accumulation을 하는 경우, 낮은 정밀도를 지속적으로 더하게 되므로 정확도가 떨어질 수 있음
train_batch_size: Integer
- 학습 배치 사이즈 설정
train_micro_batch_size_per_gpu: Integer
- GPU에 할당될 batch 크기 설정
gradient_accumulation_steps: Integer
- Gradient accumulation을 몇 번의 step마다 진행할 것인지 설정
train_batch_size = # of GPUs $\times$ train_micro_batch_szie_per_gpu $\times$ gradient_accumulation_steps
train_batch_size는 위와 같도록 설정해야 한다. DeepSpeed가 알아서 설정하도록 각 파라미터를 ‘auto’로 설정해도 된다.
gradient_clipping: Float
- Gradient clipping 값을 설정, 기본값: 1.0
communication_data_type: String
- 계산된 Gradient를 averaging할때 사용될 데이터 타입 설정
optimizer
- type, lr, decay 등 optimizer와 관련된 하이퍼파라미터를 설정
- 자동으로 설정하고 싶어면 “auto” 입력
{ "optimizer": { "type": "Optimizer Name", "params": { "lr": 1e-4, "weight_decay": "auto" } } } scheduler
- type, warmup 등 scheduler와 관련된 하이퍼파라미터를 설정
- 자동으로 설정하고 싶어면 “auto” 입력
{ "scheduler": { "type": "Scheduler Name", "params": { "warmup_min_lr": 0.0, "warmup_max_lr": "auto", "warmup_num_steps": "auto" } } } zero_optimization
ZeRO 관련 설정은 Huggingface Trainer에서 구성하지 않으므로, DeepSpeed Configuration에 반드시 수동으로 작성해 줘야 함
ZeRO-1
{ "zero_optimization": { "stage": 1 } }- ZeRO-2
offload_optimizer: Optimizer의 state의 Offloading 설정device: Offloading device 설정 (‘cpu’ or ‘nvme’)pin_memory: Page-locked CPU 메모리로 Offloading 하는 설정(디스크 스왑 방지). 처리량이 올라가지만 다른 프로세스가 사용할 수 있는 메모리 감소
allgather_partitions: All-Gather 방식으로 GPU 간 Communication 할지 설정allgather_bucket_size / reduce_bucket_size: All-Gather, All-Reduced 연산시 처리할 요소의 개수 설정. GPU 메모리와 Communication 속도의 Trade-Off를 설정하는 옵션으로 값이 작을수록 GPU 간 Communication이 많아지지만 GPU 메모리 사용량은 줄어들게 됨.overlap_comm: Backward 과정과 Gradient를 합치는(reduce) 과정을 동시에 진행하도록 하는 설정. True로 설정할 경우 GPU 메모리 사용량을 증가시키는 대신 All-Reduce 레이턴시가 감소함.contiguous_gradients: Backward 과정에서의 메모리 단편화 방지 옵션(메모리 사용량 감소, 접근 속도 향상)round_robin_gradients: CPU Offloading에 사용되는 인자로 Fine-grained Partitioning을 통해 Rank 간 CPU 메모리로의 Gradient 복사를 병렬적으로 처리함. Gradient Accumulation step과 GPU 수가 증가할수록 성능이 개선됨.{ "zero_optimization": { "stage": 2, "offload_optimizer": { "device": "nvme", "pin_memory": true }, "allgather_partitions": true, "allgather_bucket_size": 5e8, "overlap_comm": true, "reduce_bucket_size": 5e8, "contiguous_gradients": true, "round_robin_gradients": true } }
- ZeRO-3
offload_param: 모델 Parameter를 Offloading하는 설정device: Offloading device 설정 (‘cpu’ or ‘nvme’)pin_memory: Page-locked CPU 메모리로 Offloading 하는 설정(디스크 스왑 방지). 처리량이 올라가지만 다른 프로세스가 사용할 수 있는 메모리 감소
sub_group_size- Parameter들을 버켓팅하는 단위를 설정함. 한 번에 하나의 버켓에서만 업데이트가 진행됨
- CPU/GPU 메모리에서 OOM을 방지함
- Optimizer Step 단계에서 OOM 발생하는 경우: sub_group_size를 줄여 메모리 사용량을 줄인다
- Optimizer Step 단계에서 시간이 오래 걸리는 경우: sub_group_size를 늘려 대역폭을 늘린다
reduce_bucket_size / stage3_prefetch_bucket_size / stage3_param_persistence_threshold- 세 가지 파라미터는 모델의 hidden_size에 따라 달라진다고 함
- auto로 설정하여 Traniner가 자동으로 값을 할당하도록 하는 게 좋다고 함
stage3_max_live_parameters: GPU에서 release 전까지 메모리에 상주할 수 있는 최대 파라미터 수를 설정하는 옵션으로 작은 값을 주면 메모리를 덜 사용하지만 Communication 비용이 늘어남stage3_max_reuse_distance: 메모리 재사용 기간을 설정함. 낮을 값으로 설정하면 메모리 교체가 자주 일어남. Communication 오버헤드를 줄이기 위해 설정하는 옵션이며 Forward –> Backward 과정에서 Activation checkpointing 할 때 유용하게 사용됨stage3_gather_16bit_weights_on_model_save: 모델을 저장하기 전 GPU에 분할되어 있는 파라미터들을 통합하여 저장하는 옵션. 체크포인트를 불러와 학습을 계속 진행하려면 True로 설정해야 함
{ "zero_optimization": { "stage": 3, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "offload_param": { "device": "cpu", "pin_memory": true }, "overlap_comm": true, "contiguous_gradients": true, "sub_group_size": 1e9, "reduce_bucket_size": "auto", "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "stage3_max_live_parameters": 1e9, "stage3_max_reuse_distance": 1e9, "stage3_gather_16bit_weights_on_model_save": true } } ZeRO-3 Configuration 작성 예
{ "fp16": { "enable": true }, "train_batch_size": 64, "train_micro_batch_size_per_gpu": 4, "gradient_accumulation_steps": 4, "gradient_clipping": "auto", "communication_data_type": "fp16", "optimizer": { "type": "AdamW", "params": { "lr": 1.5e-05, "weight_decay": "auto" } }, "scheduler": { "type": "WarmupLR", "params": { "warmup_min_lr": 0, "warmup_max_lr": "auto", "warmup_num_steps": "auto" } }, "zero_optimization": { "stage": 3, "allgather_partitions": true, "allgather_bucket_size": 5e8, "reduce_scatter": true, "reduce_bucket_size": 5e8, "overlap_comm": false, "contiguous_gradients": true, "offload_optimizer": { "device": "cpu", "pin_memory": true, "ratio": 1, "buffer_count": 4, "fast_init": false }, "offload_param": { "device": "cpu", "pin_memory": true }, "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "sub_group_size": 1e9, "stage3_max_live_parameters": 1e9, "stage3_max_reuse_distance": 1e9, "stage3_gather_16bit_weights_on_model_save": false } } 3-2. Huggingface Trainer 적용 예
ZeRO-3를 사용하는 경우 Parameter Partitioning을 하기 때문에 모델 로드전에 Configuration이 설정되어 있어야 함. Huggingface Trainer를 사용할 경우 from_pretrained()로 모델을 불러오기 전에 DeepSpeed Configuration이 들어간 TrainingArguments를 미리 선언해 줘야 함.
training_args = transformers.TrainingArguments(..., deepspeed='ds_config.json') model = AutoModelForCausalLM.from_pretrained(model_path) trainer = Trainer(model=model, args=training_args, ...) 추가적으로 LoRA를 적용하여 학습 시 Data Type Mismatch 오류가 발생할 수 있는데, 아래와 같이 DeepSpeed에 설정해 놓은 자료형으로 모델 타입을 변환해 주면 해결할 수 있음.
training_args = transformers.TrainingArguments(..., deepspeed='ds_config.json') model = AutoModelForCausalLM.from_pretrained(model_path) model = get_peft_model(model, ...) model = model.to(torch.float16) trainer = Trainer(model=model, args=training_args, ...)